The attention module is typically extended into multiple attention modules sometimes referred to as attention heads. Multiple attention heads operate independently allowing the model to process different part of sequence differently.
Stacking multiple single-head attention layersThe transformer encoder is a stack of multiple attention heads \(num\_head\) number of times.
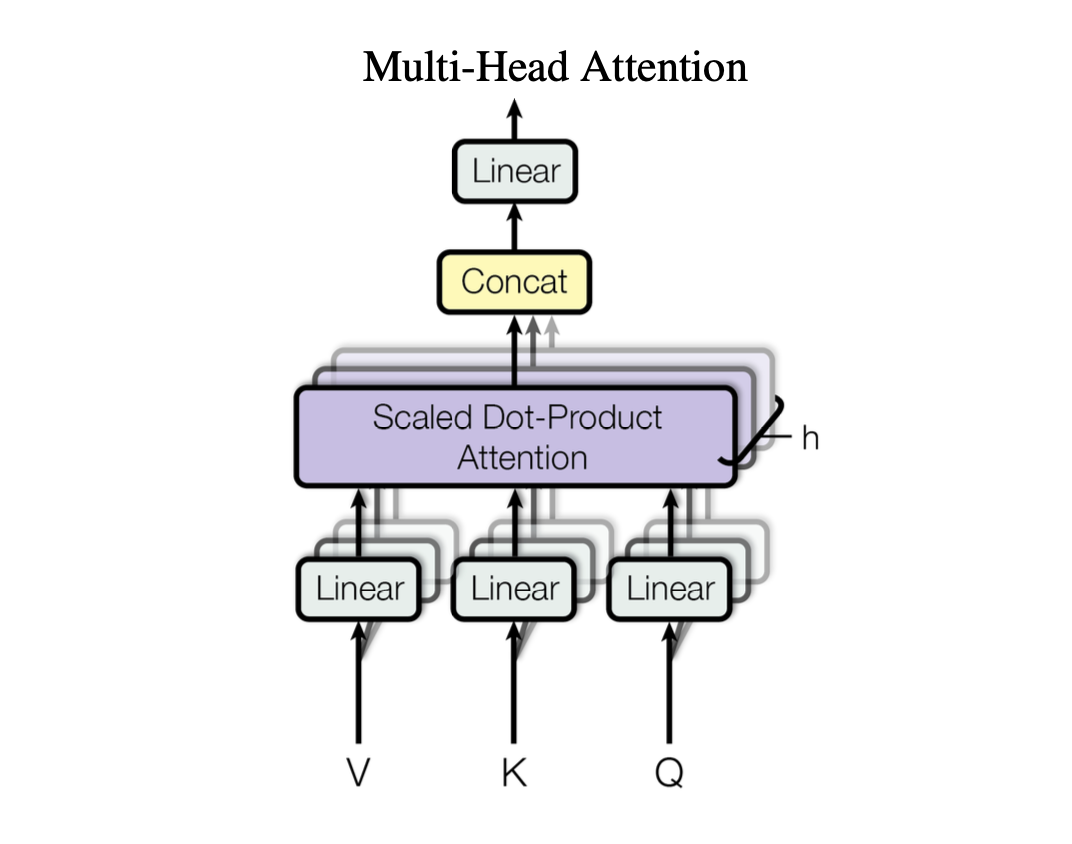
After computing the attention weights and context vectors form all heads are transposed to the shape of (b, num_tokens, num_heads, head_dim). The vectors are flattened into (b, num_tokens, d_out), effectively combining the outputs from all heads.
Benefits of Multi-Head Attention
Diverse Perspectives: By having multiple attention heads, the model can view the input data from different perspectives, allowing it to capture more complex patterns.
Reduced Overfitting: The ability to focus on various aspects of the data can help reduce the risk of overfitting, as the model doesn’t rely solely on a single representation.
Improved Performance: Multi-head attention often leads to better performance in tasks like translation, summarization, and text classification, owing to its flexibility and robustness.
References:1). Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin: “Attention Is All You Need”, 2017; arXiv:1706.03762