Byte Sized ML
About
Byte Sized ML
Categories
All
(5)
Attention
(3)
ChemBERTa
(1)
Drug Discovery
(1)
GPT2
(1)
Machine Learning
(3)
Math
(1)
Multihead-Attention
(1)
NLP
(1)
Transformers
(3)
Fine-Tuning ChemBERTa for Chemical Interaction Prediction
Machine Learning
ChemBERTa
NLP
Drug Discovery
In a recent hackathon, the Virtual Cell Program Initiative (VCPI) prediction contest hosted by Ginkgo Bioworks, I worked on predicting gene expression directly from chemical…
Jun 18, 2026
Haad Khan
Counting Number of Parameters in GPT2
Attention
Transformers
GPT2
Math
May 29, 2024
Haad Khan
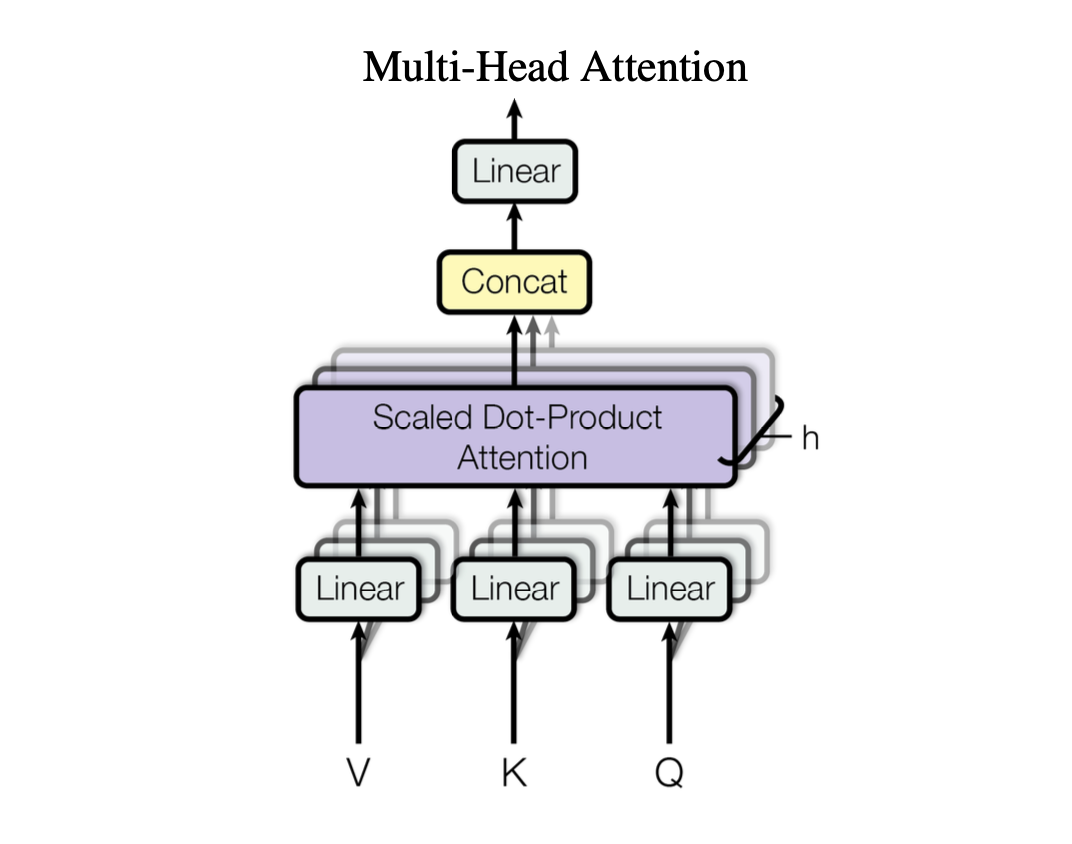
Building Blocks of Transformers: 3. Extending single-head attention to multi-head attention
Multihead-Attention
The attention module is typically extended into multiple attention modules sometimes referred to as attention heads. Multiple attention heads operate independently allowing…
Dec 1, 2023
Haad Khan
Building Blocks of Transformers: 2. Position Representation
Attention
Transformers
Machine Learning
1. Positional Encoding
Given the sequence
He can always be seen working hard.
This sequence is distinctly different from
He can hardly be seen working
. As can be seen slight…
Nov 12, 2023
Haad Khan
Building Blocks of Transformers: 1. Self Attention
Attention
Transformers
Machine Learning
I had a garbled understanding of Transformer architecture after consulting blogs, videos and coursera course. What made it finally clicked for me is Stanford CS 224N…
Nov 1, 2023
Haad Khan
No matching items